**
**
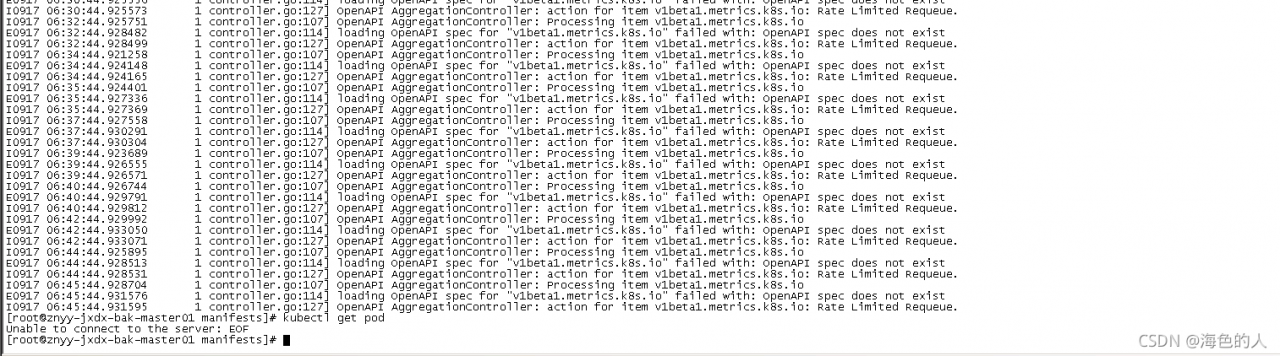 kubectl suddenly failed to obtain resources in the environment just deployed a few days ago. Check the apiserver log, as shown in the above results
kubectl suddenly failed to obtain resources in the environment just deployed a few days ago. Check the apiserver log, as shown in the above results
then the controller manager component also reports an error
E0916 08:35:55.495444 1 leaderelection.go:306] error retrieving resource lock kube-system/kube-controller-manager: Get https://192.168.1.119:8443/api/v1/namespaces/kube-system/endpoints/kube-controller-manager?timeout=10s: EOF
This environment adopts three master deployments. Then I see that VIP drifts to the master node. Both haproxy and keepalived here are container deployments. Then I restart haproxy first
docker restart xxx
iptables failed: iptables --wait -t nat -A DOCKER -p tcp -d 0/0 --dport 8443 -j DNAT
--to-destination 172.18.0.6:8443 ! -i docker0 iptables: No chain/target/match by that name
Haproxy doesn’t get up, so I guess there is something wrong with the iptables rules of the master 3 host. Then I restart it. Kept
at this time, the VIP drifts to master 1. At this time, kubectl can obtain resources
Finally, I restarted the docker component of Master 3
systemctl restatrt docker
Then manually drift the VIP to master3, and it is normal at this time