Solve the problem that hmaster hangs up due to namenode switching in Ha mode
Question:
When we build our own big data cluster for learning, the virtual machine often gets stuck and the nodes hang up inexplicably because the machine configuration is not high enough.
In Hadoop’s highly available cluster, the machine configuration is not enough, and the two namenodes always switch state automatically, resulting in the hang up of the hmaster node of the HBase cluster.
Causes of problems:
Let’s check the master log of HBase:
# Go to the log file directory
[root@hadoop001 ~]# cd /opt/module/hbase-1.3.1/logs/
[root@hadoop001 logs]# vim hbase-root-master-hadoop001.log
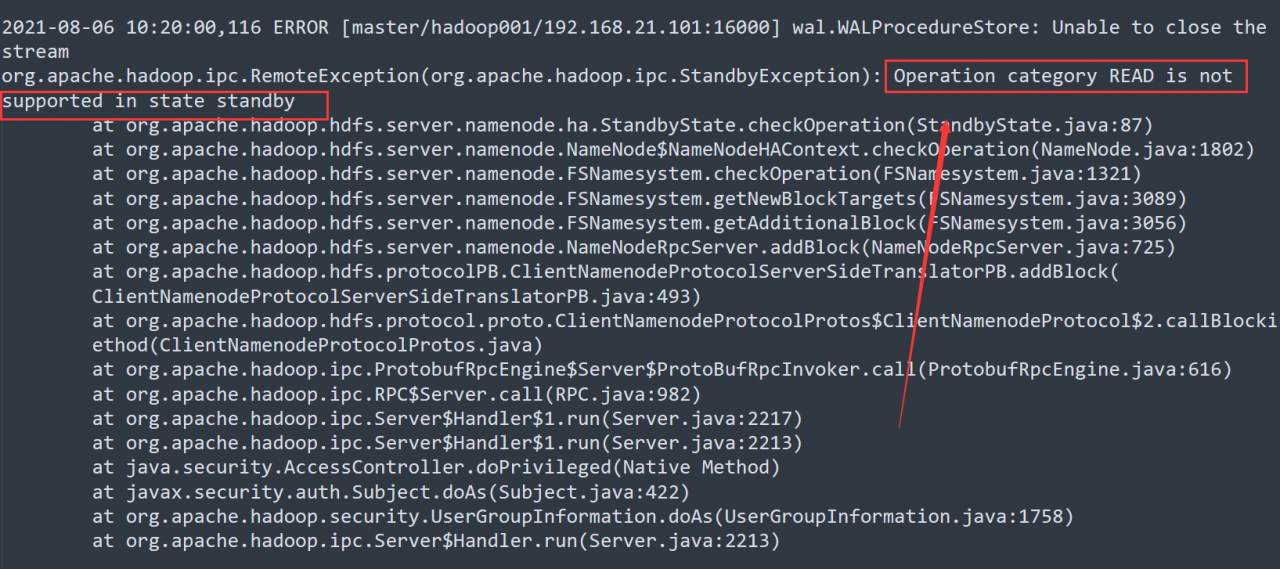
From the log, it is easy to find that the error is caused by the active/standby switching of namenode.
resolvent:
1. Modify the hbase-site.xml configuration file
Modify the configuration of base.roodir
<property>
<name>hbase.roodir</name>
<value>hdfs://hadoop001:9000/hbase</value>
</property>
# change to
<property>
<name>hbase.roodir</name>
<value>hdfs://ns/hbase</value>
</property>
# Note that the ns here is the value of hadoop's dfs.nameservices (configured in hdfs-site-xml, fill in according to your own configuration)
2. Establish soft connection
[root@hadoop001 ~]# ln -s /opt/module/hadoop-2.7.6/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.3.1/conf/hdfs-site.xml
[root@hadoop001 ~]# ln -s /opt/module/hadoop-2.7.6/etc/hadoop/core-site.xml /opt/module/hbase-1.3.1/conf/core-site.xml
3. Synchronize HBase profiles for all clusters
Use SCP instruction to distribute to other nodes
Then restart the cluster to solve the hang up problem of the hmaster node