1. Processing, Storing, and Organizing Data
</> OLAP vs. OLTP
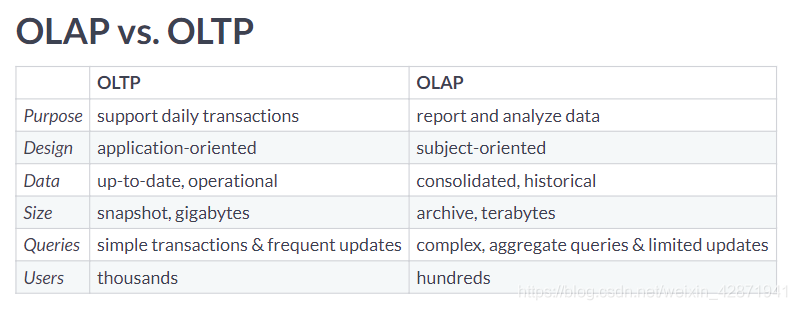
Categorize the cards into the approach that they describe best.
| OLAP | OLTP |
|---|---|
| Queries a larger amount of data | Most likely to have data from the past hour |
| Helps businesses with decision making and problem solving | Typically uses an operational database |
| Typically uses a data warehouse | Data is inserted and updated more often |
</> Which is better?
Explore the dataset. What data processing approach is this larger repository most likely using?
OLTP because this table could not be used for any analysis. OLAP because each record has a unique service request number. OLTP because this table’s structure appears to require frequent updates. OLAP because this table focuses on pothole requests only.
</> Name that data type!
Each of these cards hold a type of data. Place them in the correct category.
| Unstructured | Semi-Structured | Structured |
|---|---|---|
| To-do notes in a text editor | CSVs of open data downloaded from your local government websites | A relational database with latest withdrawals and deposits made by clients |
| Images in your photo library | JSON object of tweets outputted in real-time by the Twitter API | |
| Zip file of all text messages ever received |  |
</> Ordering ETL Tasks
In the ETL flow you design, different steps will take place. Place the steps in the most appropriate order.
eCommerce API outputs real time data of transactions
Python script drops null rows and clean data into pre-determined columns
Resulting dataframe is written into an AWS Redshift Warehouse
</> Recommend a storage solution
When should you choose a data warehouse over a data lake?
To train a machine learning model with a 150 GB of raw image data. To store real-time social media posts that may be used for future analysis To store customer data that needs to be updated regularly To create accessible and isolated data repositories for other analysts
</> Classifying data models
Each of these cards hold a tool or concept that fits into a certain type of data model. Place the cards in the correct category.
| Conceptual Data Model | Logical Data Model | Physical Data Model |
|---|---|---|
| Gathers business requirements | Relational model | File structure of data storage |
| Entities, attributes, and relationships | Determining tables and columns |
</> Deciding fact and dimension tables
Out of these possible answers, what would be the best way to organize the fact table and dimensional tables?
A fact table holding duration_mins and foreign keys to dimension tables holding route details and week details, respectively. A fact table holding week,month, year and foreign keys to dimension tables holding route details and duration details, respectively. A fact table holding route_name,park_name, distance_km,city_name, and foreign keys to dimension tables holding week details and duration details, respectively.
Create a dimension table called route that will hold the route information.
Create a dimension table called week that will hold the week information.
CREATE TABLE route(
route_id INTEGER PRIMARY KEY,
park_name VARCHAR(160) NOT NULL,
city_name VARCHAR(160) NOT NULL,
distance_km FLOAT NOT NULL,
route_name VARCHAR(160) NOT NULL
);
CREATE TABLE week(
week_id INTEGER PRIMARY KEY,
week INTEGER NOT NULL,
month VARCHAR(160) NOT NULL,
year INTEGER NOT NULL
);
</> Querying the dimensional model
Calculate the sum of the duration_mins column.
SELECT
SUM(duration_mins)
FROM
runs_fact;
sum
1172.16
Join week_dim and runs_fact.
Get all the week_id’s from July, 2019.
SELECT
SUM(duration_mins)
FROM
runs_fact
INNER JOIN week_dim ON runs_fact.week_id = week_dim.week_id
WHERE month = 'July' and year = '2019';
sum
381.46
2. Database Schemas and Normalization
</> Running from star to snowflake
After learning about the snowflake schema, you convert the current star schema into a snowflake schema. To do this, you normalize route_dim and week_dim. Which option best describes the resulting new tables after doing this?
The tables runs_fact, route_dim, and week_dim have been loaded.
week_dim is extended two dimensions with new tables for month and year. route_dim is extended one dimension with a new table for city. week_dim is extended two dimensions with new tables for month and year. route_dim is extended two dimensions with new tables for city and park. week_dim is extended three dimensions with new tables for week, month and year. route_dim is extended one dimension with new tables for city and park.
</> Adding foreign keys
In the constraint called sales_book, set book_id as a foreign key.
In the constraint called sales_time, set time_id as a foreign key.
In the constraint called sales_store, set store_id as a foreign key.
-- Add the book_id foreign key
ALTER TABLE fact_booksales ADD CONSTRAINT sales_book
FOREIGN KEY (book_id) REFERENCES dim_book_star (book_id);
-- Add the time_id foreign key
ALTER TABLE fact_booksales ADD CONSTRAINT sales_time
FOREIGN KEY (time_id) REFERENCES dim_time_star (time_id);
-- Add the store_id foreign key
ALTER TABLE fact_booksales ADD CONSTRAINT sales_store
FOREIGN KEY (store_id) REFERENCES dim_store_star (store_id);
</> Extending the book dimension
Create dim_author with a column for author.
Insert all the distinct authors from dim_book_star into dim_author.
CREATE TABLE dim_author (
author VARCHAR(256) NOT NULL
);
-- Insert authors into the new table
INSERT INTO dim_author
SELECT DISTINCT author FROM dim_book_star;
Alter dim_author to have a primary key called author_id.
Output all the columns of dim_author.
CREATE TABLE dim_author (
author varchar(256) NOT NULL
);
INSERT INTO dim_author
SELECT DISTINCT author FROM dim_book_star;
-- Add a primary key
ALTER TABLE dim_author ADD COLUMN author_id SERIAL PRIMARY KEY;
-- Output the new table
SELECT * FROM dim_author;
author author_id
F. Scott Fitzgerald 1
Barack Obama 2
Agatha Christie 3
...
</> Querying the star schema
Select state from the appropriate table and the total sales_amount.
Complete the JOIN on book_id.
Complete the JOIN to connect the dim_store_star table
Conditionally select for books with the genre novel.
Group the results by state.
SELECT dim_store_star.state, SUM(fact_booksales.sales_amount)
FROM fact_booksales
JOIN dim_book_star on fact_booksales.book_id = dim_book_star.book_id
JOIN dim_store_star on fact_booksales.store_id = dim_store_star.store_id
WHERE
dim_book_star.genre = 'novel'
GROUP BY
dim_store_star.state;
state sum
Florida 295594.2
Vermont 216282
Louisiana 176979
...
</> Querying the snowflake schema
Select state from the appropriate table and the total sales_amount.
Complete the two JOINS to get the genre_id’s.
Complete the three JOINS to get the state_id’s.
Conditionally select for books with the genre novel.
Group the results by state.
SELECT dim_state_sf.state, SUM(fact_booksales.sales_amount)
FROM fact_booksales
JOIN dim_book_sf on fact_booksales.book_id = dim_book_sf.book_id
JOIN dim_genre_sf on dim_book_sf.genre_id = dim_genre_sf.genre_id
JOIN dim_store_sf on fact_booksales.store_id = dim_store_sf.store_id
JOIN dim_city_sf on dim_store_sf.city_id = dim_city_sf.city_id
JOIN dim_state_sf on dim_city_sf.state_id = dim_state_sf.state_id
WHERE
dim_genre_sf.genre = 'novel'
GROUP BY
dim_state_sf.state;
state sum
British Columbia 374629.2
California 583248.6
Florida 295594.2
...
</> Updating countries
Output all the records that need to be updated in the star schema so that countries are represented by their abbreviations.
SELECT * FROM dim_store_star
WHERE country != 'USA' AND country !='CA';
store_id store_address city state country
798 23 Jeanne Ave Montreal Quebec Canada
799 56 University St Quebec City Quebec Canada
800 23 Verte Ave Montreal Quebec Canada
...
How many records would need to be updated in the snowflake schema?
18 records 2 records 1 record 0 records
</> Extending the snowflake schema
Add a continent_id column to dim_country_sf with a default value of 1. Note that NOT NULL DEFAULT(1) constrains a value from being null and defaults its value to 1.
Make that new column a foreign key reference to dim_continent_sf’s continent_id.
ALTER TABLE dim_country_sf
ADD continent_id int NOT NULL DEFAULT(1);
-- Add the foreign key constraint
ALTER TABLE dim_country_sf ADD CONSTRAINT country_continent
FOREIGN KEY (continent_id) REFERENCES dim_continent_sf(continent_id);
-- Output updated table
SELECT * FROM dim_country_sf;
country_id country continent_id
1 Canada 1
2 USA 1
</> Converting to 1NF
Does the customers table meet 1NF criteria?
Yes, all the records are unique. No, because there are multiple values in cars_rented and invoice_id No, because the non-key columns such as don’t depend on customer_id, the primary key.
cars_rented holds one or more car_ids and invoice_id holds multiple values. Create a new table to hold individual car_ids and invoice_ids of the customer_ids who’ve rented those cars.
Drop two columns from customers table to satisfy 1NF
-- Create a new table to satisfy 1NF
CREATE TABLE cust_rentals (
customer_id INT NOT NULL,
car_id VARCHAR(128) NULL,
invoice_id VARCHAR(128) NULL
);
-- Drop column from customers table to satisfy 1NF
ALTER TABLE customers
DROP COLUMN cars_rented,
DROP COLUMN invoice_id;
</> Converting to 2NF
Why doesn’t customer_rentals meet 2NF criteria?
Because the end_date doesn’t depend on all the primary keys. Because there can only be at most two primary keys. Because there are non-key attributes describing the car that only depend on one primary key, car_id.
Create a new table for the non-key columns that were conflicting with 2NF criteria.
Drop those non-key columns from customer_rentals.
-- Create a new table to satisfy 2NF
CREATE TABLE cars (
car_id VARCHAR(256) NULL,
model VARCHAR(128),
manufacturer VARCHAR(128),
type_car VARCHAR(128),
condition VARCHAR(128),
color VARCHAR(128)
);
-- Drop columns in customer_rentals to satisfy 2NF
ALTER TABLE customer_rentals
DROP COLUMN model,
DROP COLUMN manufacturer,
DROP COLUMN type_car,
DROP COLUMN condition,
DROP COLUMN color;
</> Converting to 3NF
Why doesn’t rental_cars meet 3NF criteria?
Because there are two columns that depend on the non-key column, model. Because there are two columns that depend on the non-key column, color. Because 2NF criteria isn’t satisfied.
Create a new table for the non-key columns that were conflicting with 3NF criteria.
Drop those non-key columns from rental_cars.
-- Create a new table to satisfy 3NF
CREATE TABLE car_model(
model VARCHAR(128),
manufacturer VARCHAR(128),
type_car VARCHAR(128)
);
-- Drop columns in rental_cars to satisfy 3NF
ALTER TABLE rental_cars
DROP COLUMN manufacturer,
DROP COLUMN type_car;
3. Database Views
</> Tables vs. views
| Only Tables | Views&Tables | Only Views |
|---|---|---|
| Part of the physical schema of a database | Contains rows and columns | Always defined by a query |
| Can be queried | Takes up less memory | |
| Has access control |
</> Viewing views
Query the information schema to get views.
Exclude system views in the results.
SELECT * FROM information_schema.views
WHERE table_schema NOT IN ('pg_catalog', 'information_schema');
What does view1 do?
SELECT content.reviewid,
content.content
FROM content
WHERE (length(content.content) > 4000);
Returns the content records with reviewids that have been viewed more than 4000 times. Returns the content records that have reviews of more than 4000 characters. Returns the first 4000 records in content.
What does view2 do?
SELECT reviews.reviewid,
reviews.title,
reviews.score
FROM reviews
WHERE (reviews.pub_year = 2017)
ORDER BY reviews.score DESC
LIMIT 10;
Returns 10 random reviews published in 2017. Returns the top 10 lowest scored reviews published in 2017. Returns the top 10 highest scored reviews published in 2017.
</> Creating and querying a view
Create a view called high_scores that holds reviews with scores above a 9.
CREATE VIEW high_scores AS
SELECT * FROM reviews
WHERE score > 9;
Count the number of records in high_scores that are self-released in the label field of the labels table.
CREATE VIEW high_scores AS
SELECT * FROM REVIEWS
WHERE score > 9;
-- Count the number of self-released works in high_scores
SELECT COUNT(*) FROM high_scores
INNER JOIN labels ON high_scores.reviewid = labels.reviewid
WHERE label = 'self-released';
count
3
</> Creating a view from other views
Create a view called top_artists_2017 with one column artist holding the top artists in 2017.
Join the views top_15_2017 and artist_title.
Output top_artists_2017.
CREATE VIEW top_artists_2017 AS
SELECT artist_title.artist FROM top_15_2017
INNER JOIN artist_title
ON top_15_2017.reviewid = artist_title.reviewid;
-- Output the new view
SELECT * FROM top_artists_2017;
artist
massive attack
krallice
uranium club
...
Which is the DROP command that would drop both top_15_2017 and top_artists_2017?
DROP VIEW top_15_2017 CASCADE; DROP VIEW top_15_2017 RESTRICT; DROP VIEW top_artists_2017 RESTRICT; DROP VIEW top_artists_2017 CASCADE;
</> Granting and revoking access
Revoke all database users’ update and insert privileges on the long_reviews view.
Grant the editor user update and insert privileges on the long_reviews view.
REVOKE update, insert ON long_reviews FROM PUBLIC;
GRANT update, insert ON long_reviews TO editor;
</> Updatable views
Which views are updatable?
long_reviews and top_25_2017 top_25_2017 long_reviews top_25_2017 and artist_title
SELECT * FROM information_schema.views
WHERE table_schema NOT IN ('pg_catalog', 'information_schema');
</> Redefining a view
Can the CREATE OR REPLACE statement be used to redefine the artist_title view?
Yes, as long as the label column comes at the end. No, because the new query requires a JOIN with the labels table. No, because a new column that did not exist previously is being added to the view. Yes, as long as the label column has the same data type as the other columns in artist_title
Redefine the artist_title view to include a column for the label field from the labels table.
CREATE OR REPLACE VIEW artist_title AS
SELECT reviews.reviewid, reviews.title, artists.artist, labels.label
FROM reviews
INNER JOIN artists
ON artists.reviewid = reviews.reviewid
INNER JOIN labels
ON labels.reviewid = reviews.reviewid;
SELECT * FROM artist_title;
reviewid title artist label
22703 mezzanine massive attack virgin
22721 prelapsarian krallice hathenter
22659 all of them naturals uranium club fashionable idiots
...
</> Materialized versus non-materialized
Organize these characteristics into the category that they describe best.
| Non-Materialized Views | Non-Materialized&Materialized Views | Materialized Views |
|---|---|---|
| Always turns up-to-date data | Can be used in a data warehouse | Stores the query result on disk |
| Better to use on write-intensive databases | Helps reduce the overhead of writing queries | Consumes more storage |
</> Creating and refreshing a materialized view
Create a materialized view called genre_count that holds the number of reviews for each genre.
Refresh genre_count so that the view is up-to-date.
CREATE MATERIALIZED VIEW genre_count AS
SELECT genre, COUNT(*)
FROM genres
GROUP BY genre;
INSERT INTO genres
VALUES (50000, 'classical');
-- Refresh genre_count
REFRESH MATERIALIZED VIEW genre_count;
SELECT * FROM genre_count;
</> Managing materialized views
Why do companies use pipeline schedulers, such as Airflow and Luigi, to manage materialized views?
To set up a data warehouse and make sure tables have the most up-to-date data. To refresh materialized views with consideration to dependences between views. To convert non-materialized views to materialized views. To prevent the creation of new materialized views when there are too many dependencies.
4. Database Management
</> Create a role
Create a role called data_scientist.
CREATE ROLE data_scientist;
Create a role called marta that has one attribute: the ability to login (LOGIN).
CREATE ROLE marta LOGIN;
Create a role called admin with the ability to create databases (CREATEDB) and to create roles (CREATEROLE).
CREATE ROLE admin WITH CREATEDB CREATEROLE;
</> GRANT privileges and ALTER attributes
Grant the data_scientist role update and insert privileges on the long_reviews view.
Alter Marta’s role to give her the provided password.
GRANT UPDATE, INSERT ON long_reviews TO data_scientist;
ALTER ROLE marta WITH PASSWORD 's3cur3p@ssw0rd';
</> Add a user role to a group role
Add Marta’s user role to the data scientist group role.
Celebrate! You hired multiple data scientists.
Remove Marta’s user role from the data scientist group role.
GRANT data_scientist TO marta;
REVOKE data_scientist FROM marta;
</> Reasons to partition
In the video, you saw some very good reasons to use partitioning. However, can you find which one wouldn’t be a good reason to use partitioning?
Improve data integrity Save records from 2017 or earlier on a slower medium Easily extend partitioning to sharding, and thus making use of parallelization
</> Partitioning and normalization
Can you classify the characteristics in the correct bucket?
| Normalization | Vertical Partitioning | Horizontal Partitioning |
|---|---|---|
| Reduce redundancy in table | Move specific columns to slower medium | Sharding is an extension on this, using multiple machines |
| Changes the logical data model | (Example) Move the third and fourth column to separate table | (Examples) Use the timestamp to move rows from Q4 in a specific table |
</> Creating vertical partitions
Create a new table film_descriptions containing 2 fields: film_id, which is of type INT, and long_description, which is of type TEXT.
Occupy the new table with values from the film table.
CREATE TABLE film_descriptions (
film_id INT,
long_description TEXT
);
-- Copy the descriptions from the film table
INSERT INTO film_descriptions
SELECT film_id, long_description FROM film;
Drop the field long_description from the film table.
Join the two resulting tables to view the original table.
CREATE TABLE film_descriptions (
film_id INT,
long_description TEXT
);
-- Copy the descriptions from the film table
INSERT INTO film_descriptions
SELECT film_id, long_description FROM film;
-- Drop the descriptions from the original table
ALTER TABLE film DROP COLUMN long_description;
-- Join to view the original table
SELECT * FROM film_descriptions
JOIN film
ON film_descriptions.film_id = film.film_id;
film_id long_description film_id title rental_duration rental_rate length replacement_cost rating release_year
1 A Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The Canadian Rockies 1 ACADEMY DINOSAUR 6 0.99 86 20.99 PG 2019
2 A Astounding Epistle of a Database Administrator And a Explorer who must Find a Car in Ancient China 2 ACE GOLDFINGER 3 4.99 48 12.99 G 2017
3 A Astounding Reflection of a Lumberjack And a Car who must Sink a Lumberjack in A Baloon Factory 3 ADAPTATION HOLES 7 2.99 50 18.99 NC-17 2019
...
</> Creating horizontal partitions
Create the table film_partitioned, partitioned on the field release_year.
CREATE TABLE film_partitioned (
film_id INT,
title TEXT NOT NULL,
release_year TEXT
)
PARTITION BY RANGE (release_year);
Create three partitions: one for each release year: 2017, 2018, and 2019. Call the partition for 2019 film_2019, etc.
CREATE TABLE film_partitioned (
film_id INT,
title TEXT NOT NULL,
release_year TEXT
)
PARTITION BY LIST (release_year);
-- Create the partitions for 2019, 2018, and 2017
CREATE TABLE film_2019
PARTITION OF film_partitioned FOR VALUES IN ('2019');
CREATE TABLE film_2018
PARTITION OF film_partitioned FOR VALUES IN ('2018');
CREATE TABLE film_2017
PARTITION OF film_partitioned FOR VALUES IN ('2017');
Occupy the new table the three fields required from the film table.
CREATE TABLE film_partitioned (
film_id INT,
title TEXT NOT NULL,
release_year TEXT
)
PARTITION BY LIST (release_year);
-- Create the partitions for 2019, 2018, and 2017
CREATE TABLE film_2019
PARTITION OF film_partitioned FOR VALUES IN ('2019');
CREATE TABLE film_2018
PARTITION OF film_partitioned FOR VALUES IN ('2018');
CREATE TABLE film_2017
PARTITION OF film_partitioned FOR VALUES IN ('2017');
-- Insert the data into film_partitioned
INSERT INTO film_partitioned
SELECT film_id, title, release_year FROM film;
-- View film_partitioned
SELECT * FROM film_partitioned;
film_id title release_year
2 ACE GOLDFINGER 2017
4 AFFAIR PREJUDICE 2017
5 AFRICAN EGG 2017
...
</> Data integration do’s and dont’s
Categorize the following items as being True or False when talking about data integration.
| False | True |
|---|---|
| Everybody should have access to sensitive data in the final view. | You should be careful choosing a hand-coded solution because of maintenance cost. |
| All your data has to be updated in real time in the final view. | Being able to access the desired data through a single view does not mean all data is stored together. |
| Automated testing and proactive alerts are not needed. | Data in the final view can be updated in different intervals. |
| You should choose whichever solution is right for the job right now. | Data integration should be business driven, e.g. what combination of data will be useful for the business. |
| After data integration all your data should be in a single table. | My source data can be stored in different physical locations. |
| Your data integration solution, hand-coded or ETL tool, should work once and then you can use the resulting view to run queries forever. | My source data can be in different formats and database management systems. |
</> Analyzing a data integration plan
Which risk is not clearly indicated on the data integration plan?
It is unclear if you took data governance into account. You didn’t clearly show where your data originated from. You should indicate that you plan to anonymize patient health records. If data is lost during ETL you will not find out.
</> SQL versus NoSQL
When is it better to use a SQL DBMS?
You are dealing with rapidly evolving features, functions, data types, and it’s difficult to predict how the application will grow over time. You have a lot of data, many different data types, and your data needs will only grow over time. You are concerned about data consistency and 100% data integrity is your top goal. Your data needs scale up, out, and down.
</> Choosing the right DBMS
Categorize the cards into the appropriate DBMS bucket.
| SQL | NoSQL |
|---|---|
| A banking application where it’s extremely important that data integrity is ensured. | Data warehousing on big data. |
| A social media tool that provides users with the oppotunities to grow their networks via connections. | |
| During the holiday shopping season, a e-commerce website needs to keep track of millions of shopping carts. | |
| A blog that needs to create and incorporate new types of content, such as images, comments, and videos. |