note: if you just want to solve this problem you can skip 1,2 and go straight to the 3 and 4 solution steps
- one-click start cluster view where the datanode’s log is
sh start-all.sh
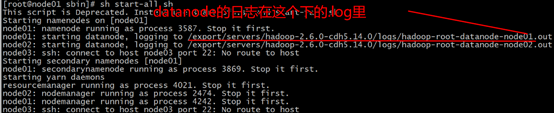
enter the log view
use shift+g to enter the last row mode, in the upward turn, see the first INFO, there is WARN below, there is a prompt message, about the datenode clusterID and namenode clusterID is not consistent.
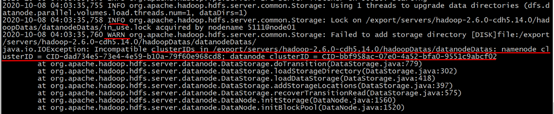
- enter CD/export/servers/hadoop – server – cdh5.14.0/hadoopDatas/datanodeDatas/current/
see cat VERSION
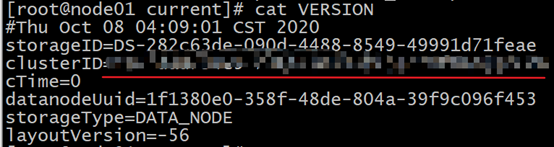
this is consistent with the namenode old ID
3. delete current

for each node in the cluster
- just restart the cluster, and check whether all the starts have been successful
sh start-all-sh
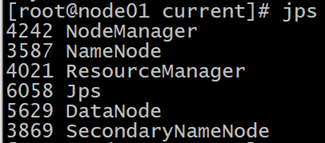
- just restart the cluster, and check whether all the starts have been successful
Read More:
- nbconvert failed: xelatex not found on PATH, if you have not installed xelatex you may need to do so
- If you open the store in iTunes, you will be prompted to solve the 310 error
- When setting up etcd cluster, an error is reported. Etcd: request cluster ID mismatch error resolution is only applicable to new etcd cluster or no data cluster
- Do you want to get fired? Let’s take a look at the programmer’s resignation tips
- If you want to open more than one program “pdc140.xxx”, the CL.EXE To write to the same. Pdb file, please use
- [unity problem] what should I do if I encounter ‘Global::’ already contains a definition
- Solve the problem that the local flow of the nifi node is inconsistent with the cluster flow, resulting in the failure to join the cluster
- error: multiple substitutions specified in non-positional format; did you mean to add the formatted
- [antdv: DatePicker] `value` provides invalidate moment time. If you want set empty value, use `null`
- How do you set, clear and toggle a single bit in C?
- Python common error: if using all scalar values, you must pass an index (four solutions)
- Convert Tencent video QLV format to MP4 format
- dfs.namenode.name . dir and dfs.datanode.data .dir dfs.name.dir And dfs.data.dir What do you mean
- A solution to the problem that the number of nodes does not increase and the name of nodes is unstable after adding nodes dynamically in Hadoop cluster
- Extract audio from ffmpeg video to mp3 format or m4a format command
- Hadoop cluster: about course not obtain block: error reporting
- Error reported when debugging Hadoop cluster under windows failed to find winutils.exe
- Solve the problem of “wireless network activation failure” in Ubuntu 18, and repeatedly pop up the password input interface
- invalid connection string format, a valid format is host:ip:port
- MySQL: if the remote connection using navicatip fails, prompt “is not allowed to connect to this MySQL server”