Error Message:
replay journal cost too much time: 1001 replayedJournalId: 462527012021-06-25 00:00:44,846 WARN (replayer|70) [BDBJournalCursor.next():149] Catch an exception when get next JournalEntity. key:46252706com.sleepycat.je.LockTimeoutException: (JE 7.3.7) Lock expired. Locker 1009050036 -1_replayer_ReplicaThreadLocker: waited for lock on database=46236602 LockAddr:1984482862 LSN=0x858/0x3c1ac4 type=READ grant=WAIT_NEW timeoutMillis=1000 startTime=1624550443846 endTime=1624550444846Owners: [<LockInfo locker="<ReplayTxn id="-48657952">970177120 -48657952_ReplayThread_ReplayTxn" type="WRITE"/>]Waiters: [<LockInfo locker="1009050036 -1_replayer_ReplicaThreadLocker" type="READ"/>]
There is a test service in the fe node bdb log error caused the fe hang, and then start can not start up, look at the doris-meta/bdb/under je.info.0 log found last night there is this error report
2021-06-24 16:00:47.926 UTC SEVERE [10.1.1.1_9010_1623157894289] 10.1.1.1_9010_1623157894289(4):/disk1/doris/doris-meta/bdb:DataCorruptionVerifier exited unexpectedly with exception java.io.IOException: Input/output errorjava.io.IOException: Input/output error
The inference is that there is a problem with the disk
dmesg -T | grep sda| grep error | tail -40
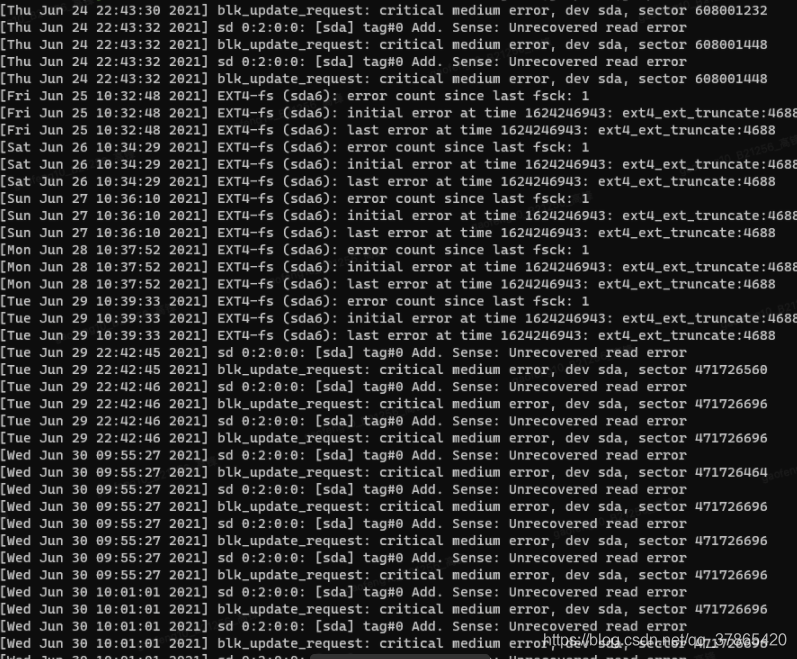
There is indeed a problem with the sector, you need to contact the IDC